Over the past couple of weeks, I and some colleagues in the Mastering Large Datasets with Python group have been practicing our new ability to scrape and process large amount of data with Spark, by harvesting public messages from the RC Zulip and analyzing them. (For those unfamiliar with Zulip, it's similar to Slack, with channels and mentions.) Although it doesn't quite qualify as "Big Data", the dataset contains ~800,000 messages, which is fodder for all sorts of questions about who posts, when, on what topics, etc. I've been focusing on implementing PageRank based on @mentions, following the book's example, and found it pretty straightforward once I performed some basic text cleanup.
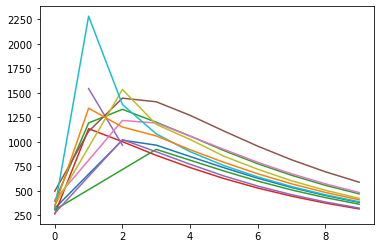
I gave a short presentation on Friday about the work done so far. Today I worked a bit on one of the next steps: a function to automatically stop the algorithm once it's run "long enough". Originally I was running it for 10 cycles, which I suspected was overkill. I started by generating a list of lists, containing the top 10 users and their ratings, for each cycle. After some massaging, I generated this graph, which shows the scores per user over time. Visual inspection suggests the ratings settle down after 4 cycles, but I'd like to calculate that directly, if possible.
I ended up writing a helper function that, given two sets of top 10 users and their ratings, first compares the users to ensure both sets are the same. If not, it returns one set of names. If so, it calculates the element-wise difference of the ratings and returns them.
def compare10(a, b):
names_a = [x[0] for x in a]
names_b = [x[0] for x in b]
if not names_a == names_b:
return names_a
else:
diffs = [(x[1] - y[1])*2/(x[1] + y[1]) for x, y in zip(a, b)]
return [round(x, 2) for x in diffs]
I called this function after a couple of rounds, to compare the current round with the previous two rounds. If the differences between subsequent rounds aren't changing, I'm comfortable declaring the loop finished. Depending on how many places I round to, this turns out to be 7, 10, or 23 cycles! I guess appearances are deceiving. (Machine learning hyperparameter tuning relies heavily on picking values off graphs, which I'm suddenly much more skeptical of...)
trace = []
finished = False
i = 0
while not finished:
if i > 0:
xs = sc.parallelize(zs.items())
acc0 = dict(xs.mapValues(pr_empty).collect())
zs = xs.aggregate(acc0, pr_acc, pr_comb)
top10 = sorted([(k, v['rating']) for k, v in zs.items()], key=lambda x: x[1], reverse=True)[:10]
if i > 1:
if compare10(top10, trace[-1]) == compare10(trace[-1], trace[-2]):
finished = True
print(i)
i += 1
trace.append(top10)